
Принцип работы поискового алгоритма
Если еще в 2016 году поисковые алгоритмы создавали видимость того, что они понимают текст путем его математического анализа. Сейчас нейронные сети способны сделать запрос и документ наиболее близкими по семантике. Одни из первых нейронок имели некоторые недостатки, среди которых утерянный порядок слов, небольшой размер словаря.
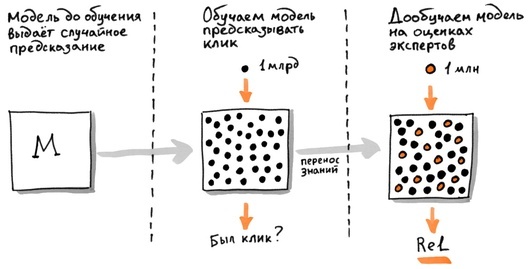
Обучение нейронных сетей основывается на миллиарде примеров. В основе таргета – предпочтение пользователей, предполагающееся по шаблону. Несмотря на это, данный подход имеет весомую неточность – неправильная интерпретация предпочтений человека. Клик необязательно говорит о том, что есть смысловая связь, так же, как если клик отсутствует, то это не показатель нерелевантности.
Самое лучшее качество – поиска можно добиться путем применения алгоритма «поисковая переформулировка». Этот алгоритм повторяет модель поведения пользователей: введение дополнительных запросов. Это требуется для получения точного результата. В основе алгоритмов Палех и Королев лежит этот принцип.
Особенность самых простых нейронных сетей заключается в дообучении, когда сеть можно легко научить выделению потока, например, коммерческих запросов. Кроме того, можно дообучить сеть на оценках экспертов. По сути, этот вид таргета самый качественный. Тренировка сети на миллиардах перефразированию пользователя и после этого на значительно меньшем числе оценок экспертов позволяет увеличить качество поиска.
Работа сетей-трансформеров
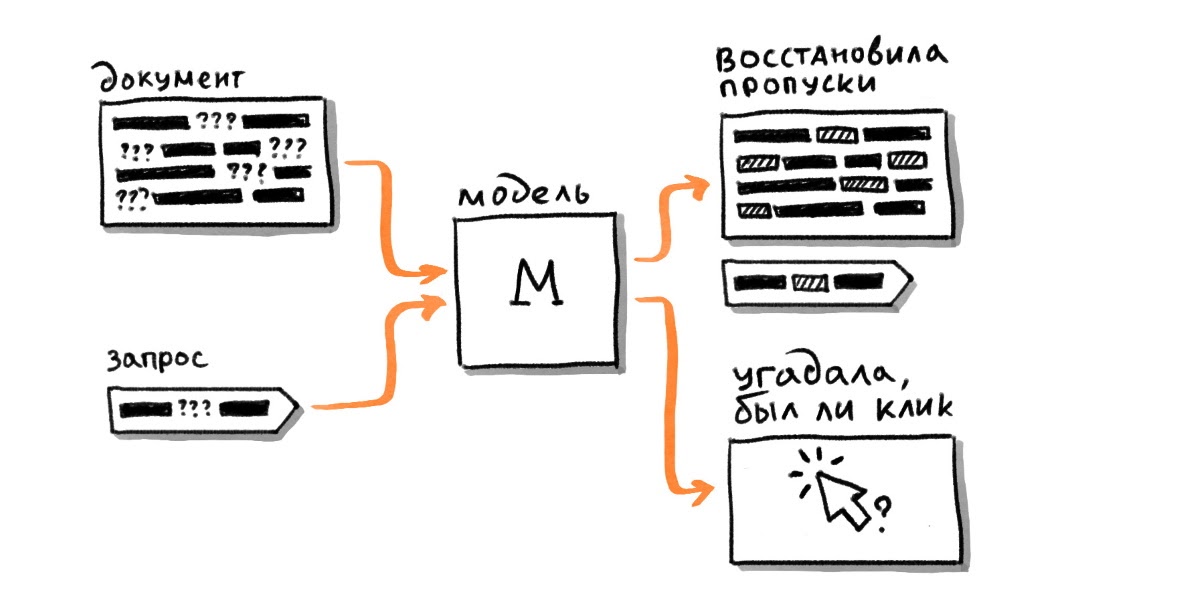
Важно отметить, что происходит отдельная обработка элементов текста. При этом положение сохраняется, задается другой вектор с использованием attention-механизма.
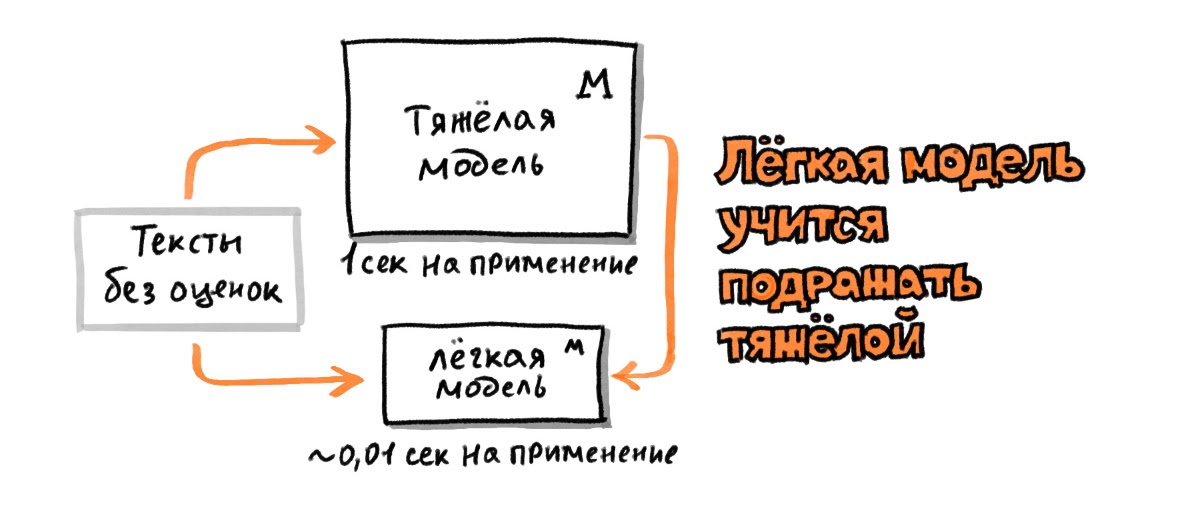
Открытая модель BERT показала на 4% увеличение качества поисковых ответов. Обучение модели BERT-base с нуля – на 10%. Модель YATI принимает во внимание контент с возможностью его извлечения из HTML-кода, а для фильтрации накрученных кликов применяются другие алгоритмы. За современными технологиями наше будущее.
